


Death From Benchmarking
Benchmarking data can cause lots of problems in the wrong hands

I don’t like it when most people review benchmarks because they don’t understand the data, how to interpret it, and how to apply it. Benchmarking data in the hands of inexperienced people creates bad outcomes. Most people are inexperienced when it comes to benchmarking data so stupid decisions are made.
People default to benchmarks as an excuse to turn off their brain — “What do the benchmarks say?”.
In this post I will cover some of the dangers of benchmarking to help people understand some of the potential issues. Also, I highly recommend attending SaaS Metrics Palooza that my friend Ray Rike hosts. This event is by far the best place to learn from the smartest people on software metrics and benchmarks.
Ultimately, the purpose of benchmarking data is to help inform if a company is on the best path toward the most successful outcome. But there are a few potential problems I want to highlight:
Averages of dissimilar companies
Reviewing data in isolation
Bad data/comparisons
Time period covered
💡Reminder: The discounted rate for the Premium OnlyCFO edition ends tomorrow. Subscribe now for the biggest discount.
Averages of Dissimilar Companies
One of my favorite 2023 SaaStr Annual talks was by Dave Kellogg where he discussed the “15 Signs of a Metric Problem”. One of those signs was:
Mis-benchmarking - comparing to the wrong companies
He said the following:
Some benchmarks are highly selection biased based on whoever answered the survey. There may be bootstrapped companies that have no outside funding, PE backed companies that want to sell in 3 years for 18x EBITDA, and you may have venture capital moon shoots who want to grow at 250% all the way up to $300M ARR.
This aggregation of dissimilar companies then spits out an average that a company might take and say is their goal…but it may actually be a really bad goal for their situation.
Dave Kellogg suggests that the best way to benchmark is by aspiration. Compare VC-backed companies looking to IPO to only other similar aspiring companies and same with PE, and bootstrapped companies.
Some benchmarks kind of do this implicitly (VC firm benchmarks generally look at their portfolio companies), but even these benchmarks may skew a certain way in other areas that make things less comparable to other companies.
The more similar the companies in the benchmark the more valuable the data. Understanding the firmographics of the companies in the benchmark is key.
Reviewing Data in Isolation
Reviewing benchmark data in isolation can cause two primary issues:
Unrealistic comparisons by cherry-picking all of the top decile metrics. You probably can’t be the best at everything and the companies in the benchmark probably aren’t either.
Hyper specialization and high spend rationalization because a holistic view isn’t taken.
While these two points are related, point #2 is where I see a lot of harm caused:
80% of company CEOs have a chief of staff…Let’s get one of those.
The median revops headcount for a $50m ARR company is [X]. We need to hire more people!
The cool companies are hiring a lot of data science people. Sounds like a smart idea.
The standard SDR to AE ratio is now 1:1, let’s hire more SDRs so we can make our reps even more efficient!
And the list of stupid stuff you can justify from benchmarks goes on forever.
Chief of Staff Example:
Some VC-backed companies may have had some success with a Chief of Staff and told some people about it so more companies got one and then lots of benchmarks said most companies had one so then everyone wanted whatever a “Chief of Staff” was. Then even earlier stage companies hired one and companies didn’t even define why they needed it. Result is Chief of Staff = overpaid EA.
Note - I think that with well-defined objectives and a clear purpose the Chief of Staff can be a high impact role for the right company.
Inefficient Specialization
The below slide came from a session at SaaStr by Sapphire Ventures. This is in line with the trend I have seen over the past ~5 years.
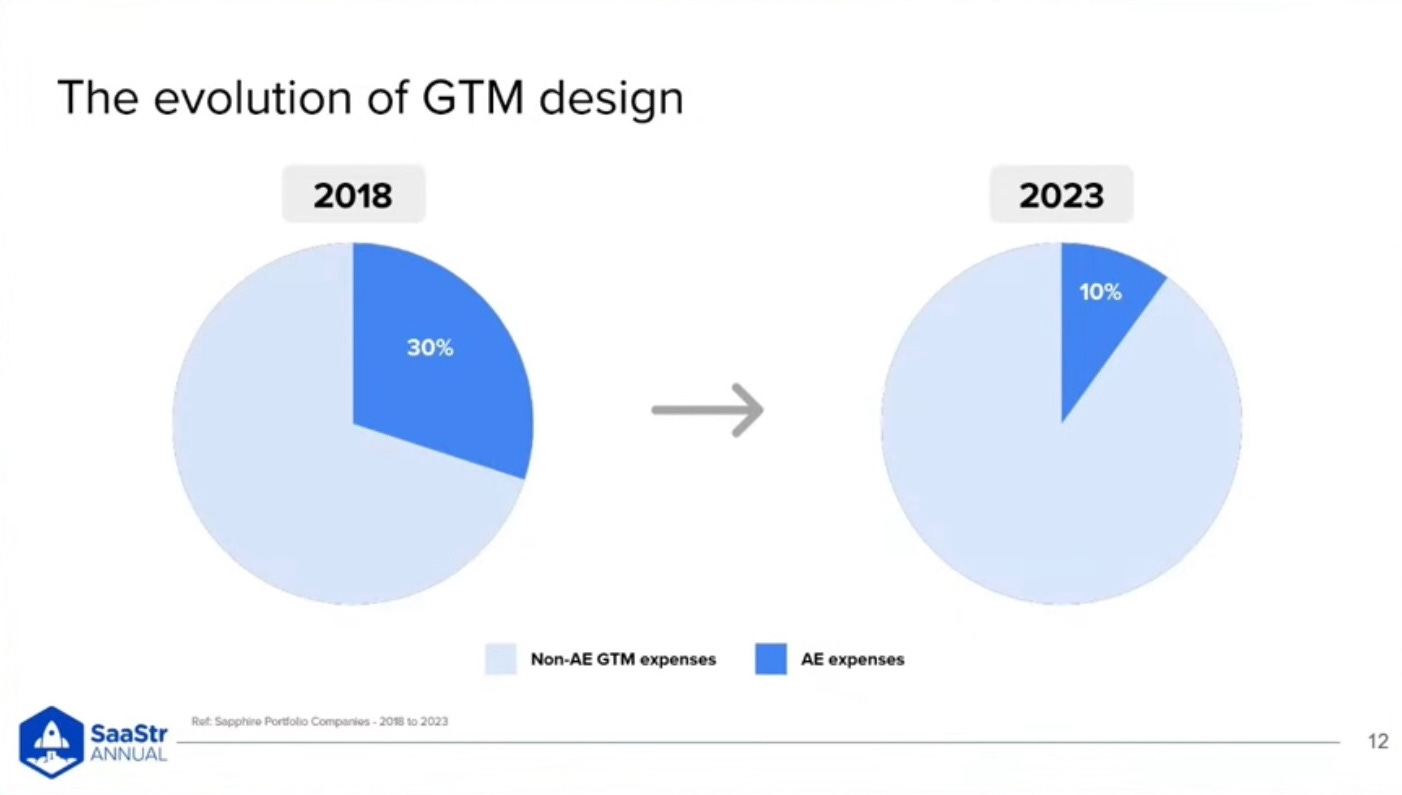
We built org structures under the premise of specialization and radically higher productivity. And all the headcount supporting the account executive (AE) exploded.
Folks looking at data in isolation will say, “It worked - our Quota:OTE ratio increased from 4x to 5x! The benchmarks say that this is a great ratio!”
But wait…
Your Go-To-Market (GTM) team is 40% bigger so you are actually significantly less efficient at acquiring customers than before. A sales rep’s Quota:OTE ratio is an efficiency indicator but ultimately it is supposed to help inform how efficient the entire GTM engine is at acquiring customers, which is all of sales & marketing.
Bad/Incomparable Data
Importance of Proper Categorization
Below is Snowflake’s latest quarterly report. Highlighted are the four primary expense categories.

Each expense is not created equal. Below are two charts that help explain the expectation difference between cost of revenue (COGS) and operating expenses (OpEx):

The median COGS as a % of revenue decreases from 33% at early stage companies to 17% for post-IPO companies. Each additional percentage point of COGS efficiency gets substantially harder than the last. Note - the median public software company COGS % is closer to 25% so the companies in this survey skew the results a bit for this group.

OpEx as a % of revenue decreased from 427% to 76%. And there is still plenty of room for these percentages to continue to decrease.
COGS % has stayed fairly flat while OpEx has shrunk 351 percentage points. This is why gross margins are such an important financial metric for investors. Gross margins set the threshold on a company’s maximum profitability potential.
Reasons for Bad Data
Now that you understand the importance of expense categorization, here are some issues benchmarks may have with expense categorization which can cause benchmarks to be less meaningful:
G&A Dumping Ground
Mostly a problem for earlier stage companies but there can be differences between large, public companies too.
Before a company has a real Controller and goes through a Big 4 audit, companies often dump a lot of expenses in G&A when they should be allocated across expense lines. Standard categories of expenses that should be allocated across expense lines include:
IT - internal IT team and software used by most of the company
Security - internal security team and software
Facilities - offices, utilities, shared expenses, etc.
Recruiting - in-house recruiting team gets allocated while outside recruiting for specific roles goes to that department.
Allocating these costs isn’t critical for early stage startups because the costs might be immaterial. But once these categories become material then it can cause problems since it will make COGS, R&D, and S&M look a lot better than they actually are. And when you finally burden these departments with these costs these expense groups will look much worse.
Incorrect Cost Attribution
Sometimes your accountants just don’t know what they are doing and are not putting expenses in the right places. This can happen for a long time and going through an audit often won’t catch this….only a good Finance team will.
For example, the Dev Ops team is charged with maintaining, troubleshooting and keeping customer software instances running. There is little debate that these folks should be categorized to COGS, but many companies incorrectly put these folks in R&D.
Methodology Differences
Even if companies didn’t have the first two problems (such as larger/public companies), there are methodology differences that exist between companies that can cause differences. A couple potential examples:
Recruiting: Some public companies put this in G&A while others allocate it across the expense lines. At several hundred million in ARR the difference is probably immaterial, but at smaller scales it can make a material difference.
Customer Success Managers (CSM): Majority of companies put 100% in S&M, but some allocate a percentage to COGS, while some may put the entire % in COGS (haven’t seen a public company do this though).
Bad Data Input
Private company benchmark surveys require someone at each of the companies to fill out the data. Sometimes the person filling it out doesn’t really understand the request and other times there is judgement involved in what to provide.
Both situations can cause bad/incomparable data to be entered…
Some benchmark surveys are better than others when collecting data.
Time Period Covered
Benchmarks performed from 2020 through early 2022 should largely be ignored today because those were unusual times. People using benchmarks need to think through the period the benchmark was performed to make sure it is still relevant and useful today.
Maybe the future impact of generative AI will make 2023 benchmarks irrelevant in a couple of years…Generative AI will likely impact metrics in numerous ways over the next few years but that impact may not show up in benchmarks for a long time.
Investor Perspective
Ultimately what matters is how much cash can a company generate at scale. This is typically represented by free cash flow (FCF) and is typically shown as a % of revenue (i.e. FCF margin). The best software companies have 30%+ FCF margins. A nit to this is to look at FCF/share because increasing free cash flow means nothing if investors are getting diluted into oblivion…
Where this FCF margin comes from doesn’t really matter — it can be from extremely high gross margins or incredibly efficient R&D, S&M, and G&A. But the assumption is that COGS moves linearly with revenue while the others have a lot of leverage.
But the differences noted in the previous sections might mean one company actually has less potential leverage than another company.
For example, imagine a company has a large customer success team that is just glorified customer support (which grows somewhat linearly with revenue) but it is included in the S&M category. Their gross margins may look great but that is just because they are hiding stuff in S&M.
Understand what companies are doing and how much leverage can actually be obtained from OpEx at scale. Companies know that gross margins are critical so they do everything they can to protect expenses from going in there, but that doesn’t mean everything else has a lot of leverage potential.
At the SaaStr Annual conference David Sacks and Jason Lempkin had an interesting convo on financials:
Sacks - “You really have to pay attention to your gross margins. Most founders don’t have the experience to do that”
Sometimes finance teams bury COGS in OpEx. There is a lot of forgiveness in pure SaaS businesses for not being operational the best [because they should have high gross margins]. Mis-attributing COGS to G&A [or elsewhere] can be fatal because a sophisticated investor at the Series C stage will point that out and your gross margins will go from 80% to 60% or whatever.
In the above example, there is now 20% of revenue that can’t fall down to profits….so the valuation difference can be huge.
Conclusion
I love benchmark reports and metrics, but don’t put this data in the hands of people who don’t understand it. A good CFO can provide the most relevant benchmarking data and help people interpret it to prevent mistakes.
Better outcomes will be made if ALL leaders (not just CFOs) understand the numbers and metrics. But if they don’t understand the data then putting this data in their hands will cause even worse outcomes…
Reading & Other
Check out CJ’s great list of benchmark reports below.

This is the kind of material that would have been amazing if it existed in my early days as a venture associate. Thank you.
Great minds think alike 😉